


Un agent IA n'est pas un chatbot amélioré. C'est une distinction fondamentale que la plupart des guides ratent dès la première ligne.
Un chatbot répond. Un agent agit. Il prend des décisions, utilise des outils, se souvient de ce qui s'est passé, et peut enchaîner des tâches complexes sans qu'un humain valide chaque étape. La différence, ce n'est pas le modèle de langage - c'est l'architecture autour.
En 2026, créer son propre agent IA n'est plus réservé aux équipes de recherche de Google ou aux startups bien financées. Une PME de 10 personnes peut déployer son premier agent fonctionnel en moins d'une journée. La vraie question n'est pas si vous devriez le faire - c'est comment le faire correctement, avec les bons outils, au bon coût, et sans finir avec un prototype qui ne tient pas en production.
Dans ce guide, on couvre tout : les 4 briques fondamentales, les 3 approches selon votre niveau technique, les vrais coûts par couche, les cas d'usage concrets, et comment donner une véritable personnalité à votre agent. À la fin, vous savez exactement quelle architecture choisir et ce que ça va vous coûter. Si vous partez de zéro sur le sujet, commencez par Qu'est-ce qu'un agent IA ? Le guide pour les entreprises en 2026 pour cadrer la définition, les cas d'usage et le budget avant d'entrer dans le technique.
Beaucoup de personnes cherchent "créer un agent IA" en pensant à un chatbot amélioré - plus intelligent, mieux configuré. C'est une confusion qui mène systématiquement vers de mauvaises décisions d'architecture.
Un chatbot suit un schéma simple : stimulus -> réponse. C'est une conversation stateless - chaque message est traité de manière isolée, sans mémoire du contexte global, sans capacité d'initiative.
Un agent IA suit un schéma radicalement différent : stimulus -> raisonnement -> action(s) -> observation du résultat -> nouveau raisonnement -> réponse. Cette boucle agentique est ce qui le rend puissant. Concrètement, ça veut dire quoi ? L'agent peut appeler une API pour récupérer des données, écrire dans un CRM, envoyer un email, créer un événement calendrier, et tout ça dans la même session, en décidant lui-même de la séquence.
L'analogie la plus juste : un chatbot, c'est un panneau d'information. Un agent, c'est un employé junior qui a accès à tous vos outils métier et qui prend des initiatives. Le piège à éviter, c'est de confondre les deux en production - un chatbot mal configuré agace les utilisateurs, un agent mal configuré modifie des données en production.
Un chatbot répond. Un agent IA agit, décide, et apprend - sans supervision humaine à chaque étape.
La notion de boucle agentique est centrale : l'agent réfléchit, agit, observe ce qui se passe, réfléchit à nouveau. C'est ce cycle qui lui permet de corriger ses erreurs en cours d'exécution, d'adapter sa stratégie selon les résultats, et de gérer des tâches qui n'ont pas de chemin linéaire prédéfini. Maintenant qu'on a posé la distinction, voyons les briques qui composent concrètement un agent.
Toute personne qui comprend ces 4 briques peut débloquer n'importe quelle architecture agentique - quelle que soit la stack technique choisie. C'est le fondement commun à tous les agents, du prototype no-code à la production full custom.
1. Le LLM - le cerveau
Le modèle de langage (LLM) est ce qui raisonne, comprend l'intention, et génère les réponses. Mais le LLM seul ne fait rien - c'est l'orchestrateur qui l'active et lui donne des instructions. Le choix du modèle impacte directement la qualité de raisonnement, le coût, et la cohérence de personnalité sur la durée.
Comparatif des LLMs pour agents IA en 2026
Quel modèle choisir selon votre contexte - qualité, coût, et contraintes RGPD.
| Modèle | Point fort | Meilleur pour | Contrainte RGPD |
|---|---|---|---|
| Claude (Anthropic) | Personnalité + instruction-following | Agents complexes, rôles définis | Oui (serveurs US/EU selon config) |
| GPT-4o mini | Rapport qualité/prix, écosystème mature | Tâches simples, volume élevé | Non (données hors UE) |
| Mistral Small | Hébergement européen, open-source | Contexte RGPD fort | Oui (hébergement UE possible) |
| DeepSeek / Qwen | Coût quasi nul | Usage non sensible uniquement | Non (serveurs hors UE, opaque) |
| Ollama / vLLM (self-hosted) | Coût marginal, contrôle total | Très haut volume, données sensibles | Oui (infrastructure interne) |
Notre retour terrain : les agents construits sur des modèles Anthropic ont une meilleure cohérence de personnalité sur la durée et suivent mieux les instructions complexes. Le coût supplémentaire est justifié pour un agent de production.
2. L'orchestrateur - le chef de projet
C'est la couche qui décide : quand appeler le LLM, quel outil utiliser, comment gérer l'état de la conversation, comment reprendre après une erreur. L'orchestrateur, c'est le vrai cœur de l'agent - pas le LLM. C'est lui qui transforme un modèle de langage en un système capable d'agir. En no-code, Make et N8N jouent ce rôle via des scénarios visuels. En code, LangGraph est aujourd'hui la référence pour des graphes d'état précis et maintenables.
3. Les outils - les bras
Ce que l'agent peut faire dans le monde réel. Chaque outil est une fonction que l'agent peut appeler quand il le juge pertinent : envoyer ou lire des emails (Gmail API), lire et écrire dans un CRM (NoCRM, HubSpot, Airtable), chercher sur internet (Tavily, Brave Search API), créer des événements (Google Calendar), générer des documents, notifier sur Slack ou Telegram, exécuter du code. Un agent sans outils est un LLM amélioré. Un agent avec 10 outils bien configurés est un vrai collaborateur. La richesse des outils détermine directement la richesse des tâches que l'agent peut accomplir.
4. La mémoire - ce qui fait la différence
Sans mémoire, chaque conversation repart de zéro. L'agent ne s'adapte pas, n'apprend rien sur vos préférences, ne se souvient pas des échanges précédents. C'est la brique la plus sous-estimée - et la plus différenciante. Il y a deux niveaux à implémenter : la mémoire court terme (le contexte de la conversation en cours, géré via la fenêtre de tokens) et la mémoire long terme (ce que l'agent retient entre les sessions). Pour la mémoire long terme, deux approches complémentaires : une base vectorielle (Supabase pgvector, Pinecone, Chroma) pour la recherche sémantique - "comment on gère les relances clients chez nous" - et une base SQL structurée pour les faits précis : préférences utilisateur, historique d'actions, données métier. C'est la combinaison des deux qui crée un agent vraiment persistant.
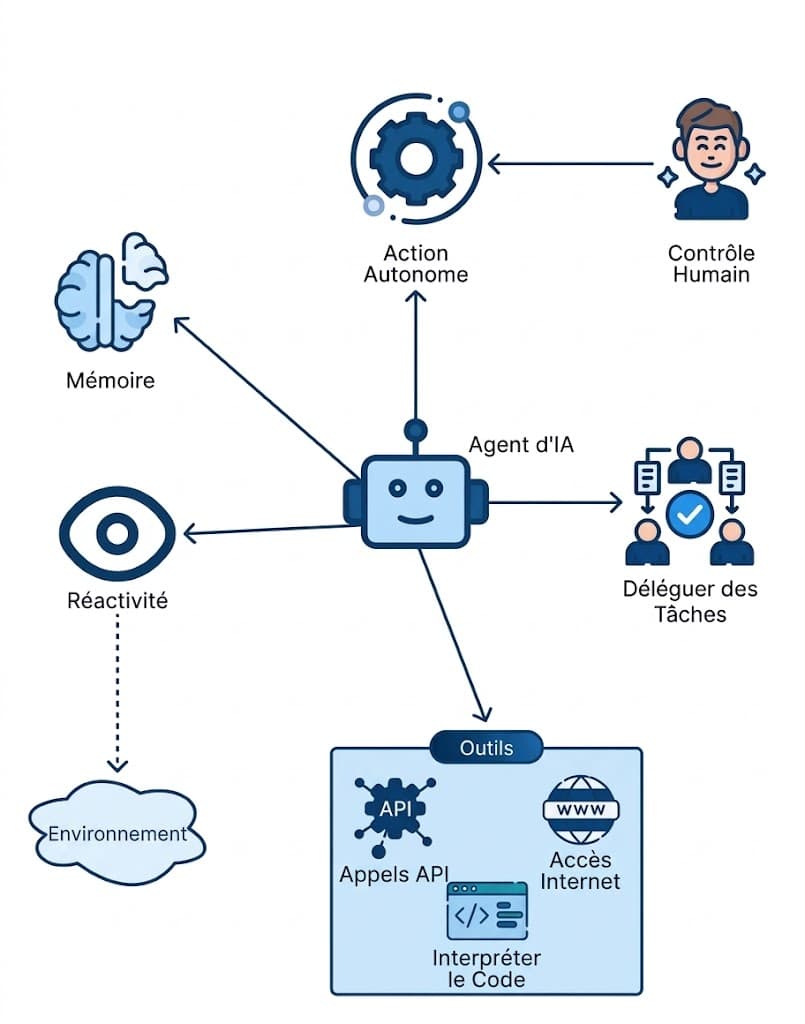
Les 4 briques fondamentales d'un agent IA - comprendre cette architecture débloque n'importe quelle stack.
Ces 4 composantes sont universelles - elles s'appliquent que vous construisiez avec Make, LangGraph, ou du Python pur. Ce qui change selon l'approche, c'est comment vous les assemblez et jusqu'où vous pouvez les pousser.
Il n'existe pas une seule façon de créer un agent IA - il en existe trois, avec des niveaux de complexité, de flexibilité et de coût radicalement différents. Le choix dépend de votre niveau technique, de vos délais, et de ce que vous voulez faire en production.
Approche 1 : No-code (Make, N8N, Flowise)
Pour qui ? Les équipes sans développeur, les PME qui veulent tester vite, les agences qui font du POC client. En quelques heures, vous câblez un agent basique, connectez des APIs sans une ligne de code, et prototypez des workflows complets (email entrant -> résumé -> réponse automatique). Le temps jusqu'au premier résultat est imbattable.
Les vraies limites, à ne pas minimiser : dès que la logique conditionnelle devient complexe, les scénarios visuels se transforment en spaghetti impossibles à maintenir. Make et N8N ne sont pas nativement conçus pour gérer la boucle agentique - réfléchir, agir, observer, reconsidérer. L'état multi-tour est difficile à gérer proprement, et versionner ou auditer ces scénarios reste un vrai défi.
Approche 2 : SDK / Framework (LangGraph, LangChain, Anthropic SDK)
Pour qui ? Les développeurs, les agences techniques, ceux qui veulent un agent reproductible et maintenable. LangGraph permet de définir des graphes d'état précis où chaque nœud est une action et chaque transition est contrôlée. Le tool calling natif avec gestion des erreurs, la mémoire hybride proprement implémentée, les tests unitaires, le versioning Git - tout ce qui manque au no-code devient possible. Concrètement : le comportement de l'agent est prévisible, debuggable, et portable. Il tourne n'importe où.
Le twist, c'est la courbe d'apprentissage : Python, async, gestion des tokens - il faut maîtriser les bases. Et l'infrastructure reste à votre charge. Entre no-code et SDK, OpenClaw propose un agent self-hosted multi-canal (Slack, Telegram) avec mémoire et personnalité — notre guide d'installation OpenClaw détaille la mise en production.
Approche 3 : Full custom production (LangGraph + Railway + Supabase + MCP)
Pour qui ? Les équipes qui veulent un agent qui vit vraiment dans leur stack, multi-plateforme, avec une mémoire sémantique profonde. C'est l'architecture la plus ambitieuse - et la plus robuste en production. La mémoire sémantique via pgvector sur Supabase permet à l'agent de retrouver des informations pertinentes dans des milliers d'entrées passées. Le MCP (Model Context Protocol) standardise les connexions aux outils externes - c'est l'avenir des intégrations agents. Et un même agent peut être accessible sur Slack, Telegram, et une interface web, avec une identité et une mémoire partagées.
Comparatif des 3 approches pour créer son agent IA
Choisissez votre architecture selon votre niveau technique, vos délais, et vos objectifs de production.
| Approche | Délai premier agent | Flexibilité | Maintenabilité | Coût mensuel estimé |
|---|---|---|---|---|
| No-code (Make / N8N) | < 1 jour | Limitée | Faible | 15 - 50€ + LLM |
| SDK / Framework (LangGraph) | 1 - 2 semaines | Totale | Bonne | 20 - 60€ + LLM |
| Full custom (LangGraph + Supabase + MCP) | Plusieurs semaines | Totale | Excellente | 50 - 150€ + LLM |
Coûts hors LLM. Pour la plupart des PME en phase de test, le no-code est le bon point de départ - avec un plan de migration vers le SDK dès que les besoins se précisent.
Quelle approche selon votre situation ?
Vous n'avez pas de développeur en interne
Commencez par le no-code pour valider l'usage, puis externalisez la migration vers SDK.
Make ou N8N permettent de tester la valeur d'un agent en quelques heures. Dès que vous avez validé qu'un agent résout un vrai problème métier, le passage à une architecture SDK est justifié. Le coût de migration est bien inférieur au coût de maintenance d'un scénario no-code complexe.
Vous avez un développeur ou une équipe technique
Allez directement sur LangGraph - le gain de temps no-code ne vaut pas la dette technique.
LangGraph avec l'Anthropic SDK offre une maîtrise totale de la logique agentique. Les tests unitaires, le versioning Git, et la gestion propre de l'état multi-tour font une différence immédiate sur la fiabilité en production. Le temps de démarrage est plus long, mais la maintenabilité sur 12 mois est sans comparaison.
Vous voulez un agent multi-plateforme avec mémoire sémantique
L'architecture full custom avec Supabase pgvector et MCP est la seule option viable.
C'est l'architecture que nous utilisons chez Volteyr pour nos agents internes. La mémoire sémantique transforme un agent générique en collaborateur qui connaît vos process, vos préférences, et l'historique de chaque interaction. Le MCP standardise les connexions aux outils externes et prépare votre stack à l'évolution rapide de l'écosystème agentique.
L'architecture choisie conditionne ce que votre agent peut faire concrètement au quotidien. Voyons maintenant les cas d'usage réels - ceux qui génèrent un ROI mesurable en entreprise.
Les cas d'usage les plus rentables ne sont pas toujours les plus spectaculaires. Ce qui génère du ROI, c'est souvent la suppression de frictions quotidiennes répétitives - pas la robotisation de processus complexes.
L'agent collaborateur interne
C'est le cas d'usage le plus immédiat et souvent le plus impactant. Imaginez un employé accessible 24h/24 sur votre Slack ou Telegram qui résume automatiquement vos appels et extrait les actions à suivre, lit votre boîte email et rédige des réponses pour validation, génère des rapports hebdomadaires à partir de vos données CRM, répond aux questions des équipes sur les process internes (congés, onboarding, FAQ), et fait du monitoring en vous alertant quand une métrique dépasse un seuil. Ce n'est pas un bot Slack avec des commandes slash. C'est un agent qui comprend le contexte, se souvient des échanges précédents, et prend des initiatives.
L'agent commercial
Qualification de leads entrants en temps réel, réponse automatique aux demandes de devis simples, relances automatisées personnalisées (pas des templates génériques), extraction d'informations depuis des appels commerciaux couplée à Fireflies.ai ou Whisper. Sur ce cas d'usage, notre client Sanala Patrimoine est passé de 20% à 50% de taux de conversion après déploiement d'un agent IA commercial dédié - en qualifiant mieux les leads avant le premier appel humain.
L'agent support client
Résolution de tickets de premier niveau, escalade intelligente vers un humain si l'agent détecte une insatisfaction ou une question hors scope, enrichissement automatique des tickets avec le contexte historique client. Impro Musique a gagné 12 leads qualifiés supplémentaires par semaine et divisé par 10 leur temps de qualification après déploiement d'un agent IA support.
L'interface vocale - le cas d'usage souvent oublié
On peut parler à son agent et l'agent répond en vocal. Deux options matures en 2026 : l'OpenAI Realtime API pour du voice-to-voice fluide en temps réel, et ElevenLabs pour une voix plus réaliste et personnalisable. C'est particulièrement utile pour des agents embarqués dans des applications mobiles ou pour des contextes mains libres - terrain, logistique, maintenance.
Sur les 12 agents IA déployés en production chez nos clients en 2025-2026, 9 sont utilisés quotidiennement par les équipes - contre 3 sur 8 l'année précédente avec des chatbots classiques.
La différence entre les deux cohortes n'est pas le modèle LLM utilisé - c'est la présence ou non d'une mémoire long terme et d'une personnalité distincte. Les agents sans mémoire sont abandonnés en moins de 3 semaines. Les agents avec mémoire persistent et évoluent dans les habitudes des équipes.
Les cas d'usage sont clairs - ce qui les fait tenir en production sur la durée, c'est la personnalité et la mémoire. Et ça, ça se construit.
C'est la section que la plupart des guides ne couvrent pas - et pourtant c'est là que se joue l'adoption réelle des équipes.
Un agent sans personnalité, c'est un outil. Un agent avec une personnalité cohérente, c'est un collaborateur. La différence se ressent immédiatement sur l'adoption interne : les équipes qui ont un agent IA avec un caractère reconnaissable l'utilisent 3 fois plus fréquemment que celles qui ont déployé un assistant générique.
Le system prompt comme acte fondateur
Tout commence là. Le system prompt n'est pas juste "tu es un assistant utile". C'est une fiche de poste complète : quel est le rôle exact de l'agent, quel est son ton (formel, direct, enthousiaste), quelles sont ses limites et ce qu'il refuse de faire, comment il s'exprime quand il ne sait pas, et quelles sont ses priorités si deux instructions se contredisent. La qualité du system prompt est systématiquement plus importante que le choix du modèle - c'est le premier enseignement que nous avons tiré de nos déploiements.
La mémoire comme vecteur d'apprentissage
La vraie personnalité émerge de la mémoire. Un agent qui se souvient de la façon dont vous préférez recevoir l'information (bullet points vs paragraphes, synthèse vs détail), des process internes ("pour les relances clients, on attend toujours 3 jours"), des préférences de chaque membre de l'équipe, et des erreurs passées ("la dernière fois, j'ai mal interprété cette demande - voilà comment j'ai corrigé") - cet agent devient progressivement un collaborateur qui s'améliore. C'est cette couche mémoire qui fait la différence entre un agent générique et un agent qui appartient à votre organisation.
L'exemple Volteyr : les réactions Slack custom
Chez Volteyr, on a poussé ça assez loin : nos agents internes ont été configurés pour utiliser nos réactions Slack custom selon le contexte. Un rapport livré déclenche une réaction spécifique. Une demande urgente, une autre. Un problème détecté, une troisième. C'est anecdotique en apparence - mais l'effet sur la perception de l'agent est immédiat. Il ne ressemble plus à un bot, il ressemble à quelqu'un qui vit dans notre Slack. L'adoption a été instantanée, sans formation, sans documentation interne.
La frontière suivante : l'agent qui s'auto-améliore
Un agent avec accès à ses propres logs peut identifier ses erreurs et proposer des modifications à son system prompt ou à ses procédures. C'est ce qu'on teste actuellement chez Volteyr - un agent avec accès à son propre code qui peut proposer des améliorations. Les résultats sont prometteurs, les risques sont réels. Attention : une boucle de validation humaine est non-négociable pour tout agent qui modifie ses propres instructions. Sans ça, les dérives sont rapides.
Nos agents internes Volteyr vivent dans Slack quotidiennement - avec une personnalité reconnaissable qui accélère l'adoption.
La personnalité est résolue par le system prompt et la mémoire. Les coûts, eux, dépendent de l'architecture et du volume. Décortiquons ça sans langue de bois.
C'est une des questions les plus cherchées et les moins bien répondues dans les articles existants. La plupart des guides parlent du coût LLM, ignorent l'infrastructure, et oublient le temps de développement. Voici la décomposition réelle, par couche.
Coût = Infrastructure + LLM + Développement
Coûts d'infrastructure par approche
Coûts mensuels estimés hors LLM, pour un agent déployé en production.
| Approche | Outils | Coût mensuel estimé |
|---|---|---|
| No-code | Make Pro + N8N cloud | 15 - 50€/mois |
| SDK / Framework | Railway ou Render + Supabase | 20 - 60€/mois |
| Full custom | Railway + Supabase Pro + monitoring | 50 - 150€/mois |
Coûts moyens constatés sur nos déploiements clients 2025-2026. Hors coûts LLM.
Le coût LLM : la variable la plus difficile à prévoir
Le coût dépend du volume de tokens consommés à chaque appel. Les ordres de grandeur à retenir : Claude Sonnet est le meilleur choix pour les agents complexes avec raisonnement approfondi - coût plus élevé, mais qualité et cohérence de personnalité supérieures. Claude Haiku et GPT-4o mini sont ultra rapides et économiques - parfaits pour les tâches de classification, routing, ou réponses simples. Mistral Small est compétitif en coût avec une bonne option RGPD, légèrement en retrait sur le suivi d'instructions complexes.
Attention au self-hosting LLM
Self-hoster un LLM open-source (LLaMA, Mistral, DeepSeek via Ollama ou vLLM) donne un coût marginal quasi nul une fois l'infrastructure en place - mais il faut du GPU. Un serveur avec un A100 ou H100 coûte entre 500€ et 2 000€/mois selon les providers. Viable pour du très haut volume ou des données ultra-sensibles, pas pour démarrer.
Les modèles chinois : la ligne rouge
DeepSeek et Qwen affichent des performances impressionnantes à un coût dérisoire. Le problème est simple : vos données passent sur des serveurs hors UE, avec des politiques de confidentialité opaques. Pour tout contexte métier sensible - clients, contrats, RH, données financières - c'est une ligne rouge. Le gain financier ne compense pas le risque de conformité.
Les coûts sont clairs. Ce qui donne le vrai contexte, c'est ce qu'on a appris en les déployant réellement - voici notre retour terrain sans filtre.
Chez Volteyr, nos premiers "employés IA" ne sont plus des prototypes. Ils vivent dans notre Slack quotidiennement, assistent à nos process, résument nos appels, gèrent des parties de notre reporting, et interagissent avec l'équipe avec une personnalité qui leur est propre.
Quatre enseignements nets après plusieurs mois de production réelle :
La qualité du system prompt est plus importante que le choix du modèle. Un Claude Haiku avec un system prompt précis surpasse un Claude Sonnet avec un prompt générique sur 90% des tâches opérationnelles.
La mémoire long terme est le vrai différenciateur. Sans elle, l'agent reste "bête" - il répète les mêmes erreurs, ne s'adapte pas au contexte de l'entreprise, et est abandonné en quelques semaines.
L'adoption interne est beaucoup plus rapide quand l'agent a une personnalité distincte. Les équipes n'ont pas besoin de formation - elles découvrent naturellement les capacités de l'agent parce qu'elles ont envie d'interagir avec lui.
Les boucles de validation humaine sont non-négociables pour tout agent qui agit (envoie des emails, modifie des données, prend des décisions avec des effets réels). Un agent trop autonome sans circuit de validation est un risque opérationnel - pas une opportunité.
On est en train de tester un agent avec accès à son propre code source, capable de proposer des améliorations à ses procédures. Si les résultats sont au rendez-vous, on publie un article dédié. Si vous voulez construire votre premier agent IA ou faire auditer votre architecture actuelle, c'est exactement ce qu'on fait chez Volteyr.



